Big Data for better insights
- Use location and other data to your advantage
- Determine which insight you want
- Pay per report
Proximus Analytics
Proximus Analytics will give you a better understanding of what is going on inside a certain zone at specific times.
How many people are present in the zone? Where do they come from? Who are they? How do they move around? How long do they stay? How often do they return? What is the financial impact?
Proximus Analytics is a tool that allows you to create and order reports very easily.

Use location data and other data sources
Measuring is knowing. By better understanding your customer or visitor, you can adapt your strategy to better meet their needs or even identify their needs and behaviour.
This information is especially useful for:
- The public sector: cities, towns and authorities
- Large-scale distribution
- Retail
- Mobility
- Tourism
- Events
Big Data Solutions
We offer both custom solutions and specific reports that are easy to order by subscribing to Proximus Analytics.
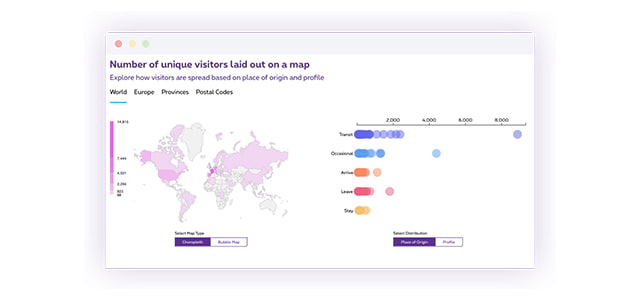
Gain insights into the visitors of a specific event or location (postal code, square, province, ...), within a specific period of time. Enrich your insights into origins and profiles to continuously optimize your marketing and business needs.
- Number of visitors in a specific area
- Origin and profile of visitors
- Duration and frequency of stay
Gain more insights into the journeys of people in or through a specific area, on ad hoc or regular basis, within a specific period of time.
- Origin and destination of journeys
- Amount of people detected in a selected area
- Identify journey patterns

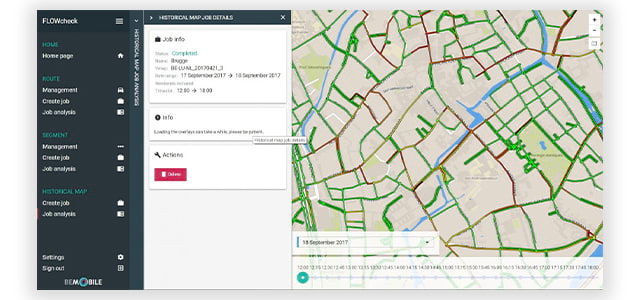
Monitor traffic flows in real time based on the combined data of road segments and people's mobility behavior. By combining historical positions of millions of connected vehicles with data from sensors along the road or at car parks, useful data for traffic management is created.
- Predict and monitor traffic congestion
- Travel routes and duration for specific journeys
- Origin and destination of traffic
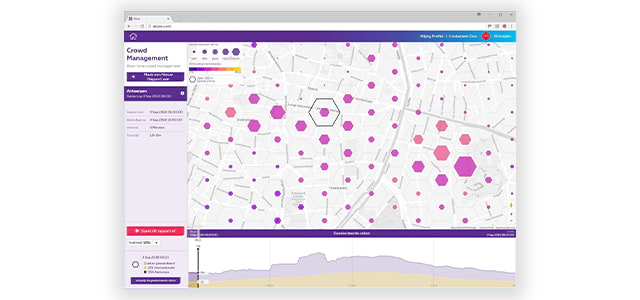
Measure the heartbeat of an event, a demonstration or a gathering. Monitor during a specific time window of an activity and react quicker and more efficiently to (un)expected situations. The aggregated data in an area refer to both the national and international crowds.
- Monitor real-time group movements
- Follow group formation and disbursement
- Sight on the best diversion paths
Demographic information tells us more about visitors in terms of social status, family composition, income class, work status, gender and age. This information is generally used to distinguish people with specific social characteristics, such as people with children, seniors, upper middle class people, etc. In order to respect privacy, this information is always collected at group level and not on an individual basis.

This visitor or event report was created by a leading payment service provider based on payment data. The report provides insight into the general spending trends of groups of people measured in a specific area over a specific period of time. The report offers added value by identifying local trends and insights.

Supplies specific insights by crossing data with data from other MyAnalytics reports or other external data sources.
How does it work?
Source
When a user’s mobile connects to mobile antennas, it provides location data. This data can be reuse for insights and statistics. The user could be local subscribers or international subscribers travelling in Belgium.
Privacy
Proximus fully respects the privacy of its customers. All data in the reports are anonymized and aggregated. We only draw up reports if there are at least 30 people active in a region.
Custom build solution
Location based anonymised data are processed and can be combined with other data sources coming from public source (eg StatBel) or from data of partners or even with data from your data base.
Get to know your customer better thanks to data analysis
Some references
As a retailer it is essential to understand both existing and potential customers in order to make better decisions and grow in a competitive market.
The collected data about the movement and behavior of people in and around your store or existing promotional areas will help you make decisions about future business activities, whether that be an optimized shopping experience for your customers, a new OOH campaign or a new store location.

For events it is interesting to know exactly how many visitors were present, where they came from and how long they stayed.
When an event organizer has all this information at his disposal, he can offer visitors a better service, optimize different zones and act more efficiently in emergency situations.

Today, tourism organizations do not have a lot information about visitor origin and profile. It’s equally hard to know when and how many people visit a tourist attraction, a specific city area or any other area of interest.
Current research methods are cumbersome and cover only a small sample, while available information, such as overnight stays at hotels, or number of entries at different attractions, is limited and may only be available long after the facts.

Local, regional or national governments need to support the interests of a wide variety of stakeholders to make cities or regions more successful. You want to get insight in the number of visitors to public events, tourist attractions or shopping malls so that parking availability, opening hours and retail offerings can be optimized.
By understanding the movement of people, you are able to solve mobility issues and ensure that everyone feels safe during public events or in public areas.

For both local, regional or national governments and mobility organizations information about journeys and movements of people it is essential to improve the traffic flow of citizens and visitors from, to and in a city or area.
A commercial company concerned with transportation and logistics wants to plan its itineraries as much as possible around major congestions points and optimize delivery routes. With location and other data insights you may learn from the past and plan better for the future. With our real-time data feeds you can start managing the situation dynamically.
![]()
Security officers are faced with multiple challenges in today’s dynamic world. Crowds are often expected and security risks must be evaluated and addressed in advance. With insights in people movements at past happenings you can better anticipate security measures at upcoming events.
But insight is not enough. Crowds and security challenges may arise quickly or unexpectedly with the help of social or other media.
COVID-19 activity report
The governments' exit plan has an impact on the mobility and citizens' professional and private activities. Proximus Data Analytics tools allow you to measure and monitor these changes
Knokke
To measure is to know
During the Light Festival Proximus helped smart city Knokke to objectify its policy and improve its services with the help of smart technology and data analytics. The full story can be found in this video.
In smart cities, objective data is essential for policy development and assessment afterwards.
Anthony Wittesaele, Alderman of tourism, Knokke-Heist